Abstract
Novel view acoustic synthesis (NVAS) aims to render binaural audio at any target viewpoint, given a mono audio emitted by a sound source at a 3D scene. Existing methods have proposed NeRF-based implicit models to exploit visual cues as a condition for synthesizing binaural audio. However, in addition to low efficiency originating from heavy NeRF rendering, these methods all have a limited ability of characterizing the entire scene environment such as room geometry, material properties, and the spatial relation between the listener and sound source. To address these issues, we propose a novel Audio-Visual Gaussian Splatting (AV-GS) model. To obtain a material-aware and geometry-aware condition for audio synthesis, we learn an explicit point-based scene representation with an audio-guidance parameter on locally initialized Gaussian points, taking into account the space relation from the listener and sound source. To make the visual scene model audio adaptive, we propose a point densification and pruning strategy to optimally distribute the Gaussian points, with the per-point contribution in sound propagation (e.g., more points needed for texture-less wall surfaces as they affect sound path diversion). Extensive experiments validate the superiority of our AV-GS over existing alternatives on the real-world RWAS and simulation-based SoundSpaces datasets.
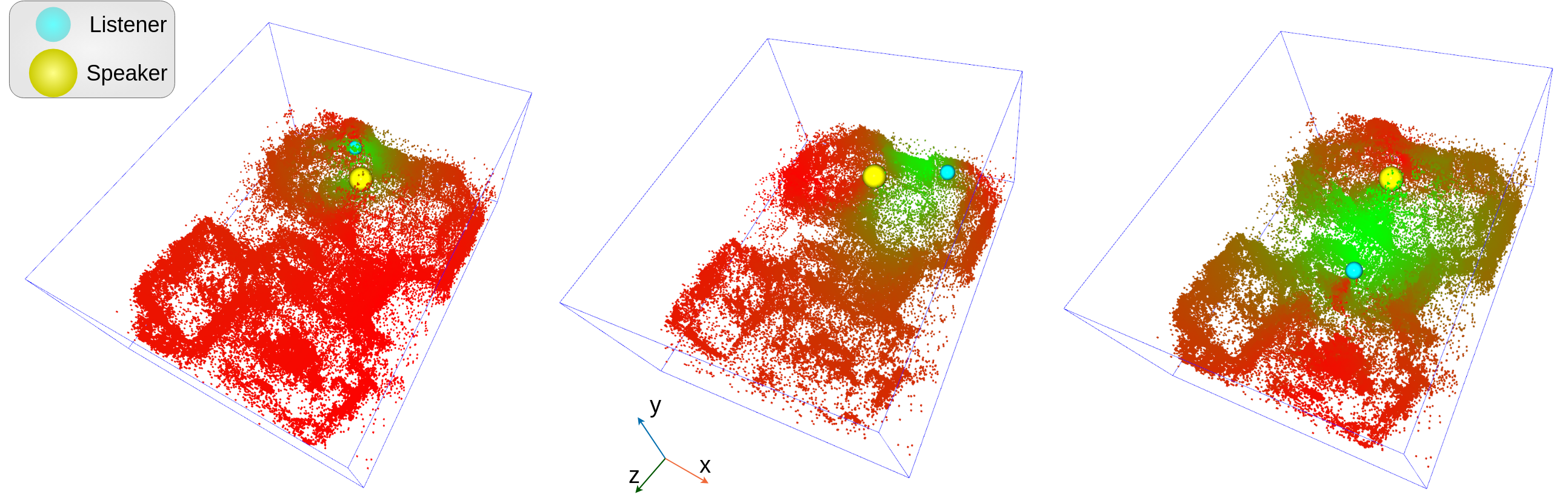
Method
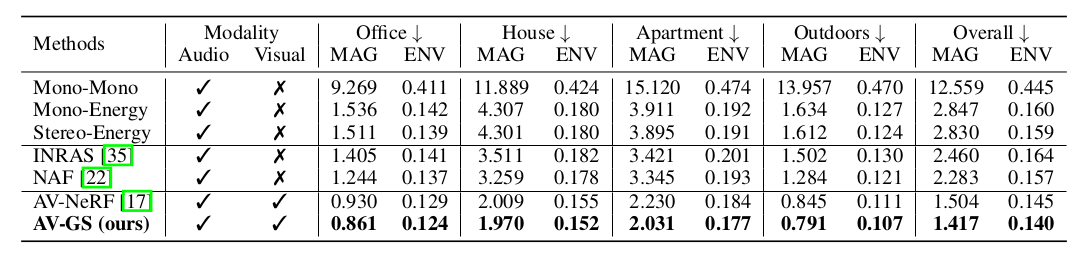
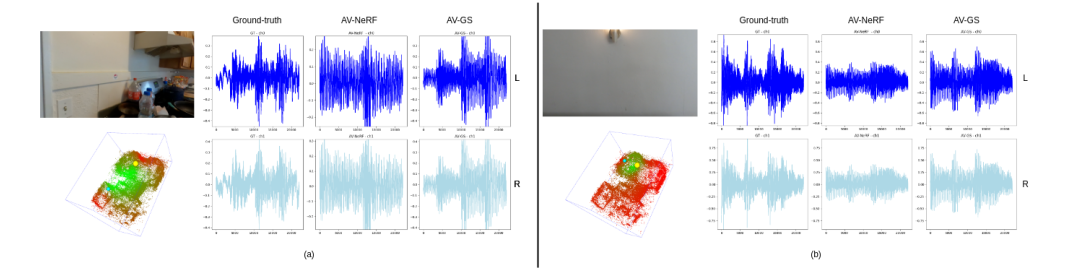
Results